Antoine Beaupr : how to audit for open services with iproute2
The computer world has a tendency of reinventing the wheel once in a
while. I am not a fan of that process, but sometimes I just have to
bite the bullet and adapt to change. This post explains how I adapted
to one particular change: the
netstat to sockstat transition.
I used to do this to show which processes where listening on which
port on a server:
netstat -anpe
-a), not resolve hostnames (-n, because it's slow), show
processes attached to the socket (-p) with extra info like the user
(-e). This still works, but sometimes fail to find the actual
process hooked to the port. Plus, it lists a whole bunch of UNIX
sockets and non-listening sockets, which are generally irrelevant
for such an audit.
What I really wanted to use was really something like:
netstat -pleunt sort
-l) and network sockets, specifically UDP (-u) and TCP
(-t).
But enough with the legacy, let's try the brave new world of sockstat
which has the unfortunate acronym ss.
The equivalent sockstat command to the above is:
ss -pleuntO
-O flag otherwise ss
does that confusing thing where it splits the output on multiple
lines. But I actually use:
ss -plunt0
-e as the information it gives (cgroup, fd
number, etc) is not much more useful than what's already provided with
-p (service and UID).
All of the above also show sockets that are not actually a concern
because they only listen on localhost. Those one should be filtered
out. So now we embark into that wild filtering ride.
This is going to list all open sockets and show the port number and
service:
ss -pluntO --no-header sed 's/^\([a-z]*\) *[A-Z]* *[0-9]* [0-9]* *[0-9]* */\1/' sed 's/^[^:]*:\(:\]:\)\?//;s/\([0-9]*\) *[^ ]*/\1\t/;s/,fd=[0-9]*//' sort -gu
anarcat@angela:~$ sudo ss -pluntO --no-header sed 's/^\([a-z]*\) *[A-Z]* *[0-9]* [0-9]* *[0-9]* */\1/' sed 's/^[^:]*:\(:\]:\)\?//;s/\([0-9]*\) *[^ ]*/\1\t/;s/,fd=[0-9]*//' sort -gu
[::]:* users:(("unbound",pid=1864))
22 users:(("sshd",pid=1830))
25 users:(("master",pid=3150))
53 users:(("unbound",pid=1864))
323 users:(("chronyd",pid=1876))
500 users:(("charon",pid=2817))
631 users:(("cups-browsed",pid=2744))
2628 users:(("dictd",pid=2825))
4001 users:(("emacs",pid=3578))
4500 users:(("charon",pid=2817))
5353 users:(("avahi-daemon",pid=1423))
6600 users:(("systemd",pid=3461))
8384 users:(("syncthing",pid=232169))
9050 users:(("tor",pid=2857))
21027 users:(("syncthing",pid=232169))
22000 users:(("syncthing",pid=232169))
33231 users:(("syncthing",pid=232169))
34953 users:(("syncthing",pid=232169))
35770 users:(("syncthing",pid=232169))
44944 users:(("syncthing",pid=232169))
47337 users:(("syncthing",pid=232169))
48903 users:(("mosh-client",pid=234126))
52774 users:(("syncthing",pid=232169))
52938 users:(("avahi-daemon",pid=1423))
54029 users:(("avahi-daemon",pid=1423))
anarcat@angela:~$
ss -pluntO --no-header \
sed 's/^\([a-z]*\) *[A-Z]* *[0-9]* [0-9]* *[0-9]* */\1/;s/^tcp//;s/^udp//' \
grep -v -e '^\[fe80::' -e '^127.0.0.1' -e '^\[::1\]' -e '^192\.' -e '^172\.' \
sed 's/^[^:]*:\(:\]:\)\?//;s/\([0-9]*\) *[^ ]*/\1\t/;s/,fd=[0-9]*//' \
sort -gu
anarcat@angela:~$ sudo ss -pluntO --no-header sed 's/^\([a-
z]*\) *[A-Z]* *[0-9]* [0-9]* *[0-9]* */\1/;s/^tcp//;s/^udp//'
grep -v -e '^\[fe80::' -e '^127.0.0.1' -e '^\[::1\]' -e '^192\.' -
e '^172\.' sed 's/^[^:]*:\(:\]:\)\?//;s/\([0-9]*\) *[^ ]*/\
1\t/;s/,fd=[0-9]*//' sort -gu
22 users:(("sshd",pid=1830))
500 users:(("charon",pid=2817))
631 users:(("cups-browsed",pid=2744))
4500 users:(("charon",pid=2817))
5353 users:(("avahi-daemon",pid=1423))
6600 users:(("systemd",pid=3461))
21027 users:(("syncthing",pid=232169))
22000 users:(("syncthing",pid=232169))
34953 users:(("syncthing",pid=232169))
35770 users:(("syncthing",pid=232169))
48903 users:(("mosh-client",pid=234126))
52938 users:(("avahi-daemon",pid=1423))
54029 users:(("avahi-daemon",pid=1423))
lsof can do
some of this, and it's relatively straightforward. This lists all
listening TCP sockets:
lsof -iTCP -sTCP:LISTEN +c 15 grep -v localhost sort
lsof -i @localhost
grep -v localhost line.
In theory, this would do the equivalent on UDP
lsof -iUDP -sUDP:^Idle
lsof: no UDP state names available: UDP:^Idle
ss can
figure out the state of those sockets, heck it's how -l vs -a
works after all. So we need something else to show listening UDP
sockets.
The following actually looks pretty good after all:
ss -pluO
localhost sockets of course, so we can explicitly ask
ss to resolve those and filter them out with something like:
ss -plurO grep -v localhost
ss supports pattern matching, so we can actually
tell it to ignore localhost directly, which removes that horrible
sed line we used earlier:
ss -pluntO '! ( src = localhost )'
ss -nplutO '! ( src = localhost )' \
sed 's/\(udp\ tcp\).*:\([0-9][0-9]*\)/\2\t\1\t/;s/\([0-9][0-9]*\t[udtcp]*\t\)[^u]*users:(("/\1/;s/".*//;s/.*Address:Port.*/Netid\tPort\tProcess/' \
sort -nu
anarcat@angela:~$ sudo ss -nplutO '! ( src = localhost )' sed 's/\(udp\ tcp\).*:\([0-9][0-9]*\)/\2\t\1\t/;s/\([0-9][0-9]*\t[udtcp]*\t\)[^u]*users:(("/\1/;s/".*//;s/.*Address:Port.*/Port\tNetid\tProcess/' sort -nu
Port Netid Process
22 tcp sshd
500 udp charon
546 udp NetworkManager
631 udp cups-browsed
4500 udp charon
5353 udp avahi-daemon
6600 tcp systemd
21027 udp syncthing
22000 udp syncthing
34953 udp syncthing
35770 udp syncthing
48903 udp mosh-client
52938 udp avahi-daemon
54029 udp avahi-daemon


 In 2022 I read 34 books (-19% on last year).
In 2021 roughly a quarter of the books I read were written by women. I was
determined to push that ratio in 2022, so I made an effort to try and only
read books by women. I knew that I wouldn't manage that, but by trying to, I
did get the ratio up to 58% (by page count).
I'm not sure what will happen in 2023. My to-read pile has some back-pressure
from books by male authors I postponed reading in 2022 (in particular new works
by Christopher Priest and Adam Roberts). It's possible the ratio will swing
back the other way, which would mean it would not be worth repeating the
experiment. At least if the ratio is the point of the exercise. But perhaps it
isn't: perhaps the useful outcome is more qualitative than quantitative.
I tried to read some new (to me) authors. I really enjoyed Shirley Jackson (The
Haunting of Hill House, We Have Always Lived In The Castle). I Struggled with
Angela Carter's Heroes and Villains although
I plan to return to her other work, in particular, The Bloody Chamber. I
also got through Donna Tartt's The Secret History on the recommendation of a
friend. I had to push through the first 15% or so but it turned out to be worth
it.
In 2022 I read 34 books (-19% on last year).
In 2021 roughly a quarter of the books I read were written by women. I was
determined to push that ratio in 2022, so I made an effort to try and only
read books by women. I knew that I wouldn't manage that, but by trying to, I
did get the ratio up to 58% (by page count).
I'm not sure what will happen in 2023. My to-read pile has some back-pressure
from books by male authors I postponed reading in 2022 (in particular new works
by Christopher Priest and Adam Roberts). It's possible the ratio will swing
back the other way, which would mean it would not be worth repeating the
experiment. At least if the ratio is the point of the exercise. But perhaps it
isn't: perhaps the useful outcome is more qualitative than quantitative.
I tried to read some new (to me) authors. I really enjoyed Shirley Jackson (The
Haunting of Hill House, We Have Always Lived In The Castle). I Struggled with
Angela Carter's Heroes and Villains although
I plan to return to her other work, in particular, The Bloody Chamber. I
also got through Donna Tartt's The Secret History on the recommendation of a
friend. I had to push through the first 15% or so but it turned out to be worth
it.




 A new release of our
A new release of our 
 The second day was opened by Florian Westphal (Netfilter coreteam member and Red Hat engineer). Florian has been
trying to improve nftables performance in kernels with RETPOLINE mitigations enabled. He commented that several
workarounds have been collected over the years to avoid the performance penalty of such mitigations.
The basic strategy is to avoid function indirect calls in the kernel.
Florian also described how BPF programs work around this more effectively. And actually, Florian tried translating
The second day was opened by Florian Westphal (Netfilter coreteam member and Red Hat engineer). Florian has been
trying to improve nftables performance in kernels with RETPOLINE mitigations enabled. He commented that several
workarounds have been collected over the years to avoid the performance penalty of such mitigations.
The basic strategy is to avoid function indirect calls in the kernel.
Florian also described how BPF programs work around this more effectively. And actually, Florian tried translating
 Finally, after many interesting debates over two days, the workshop ended. We all agreed on the need for extending
it to 3 days next time, since 2 days feel too intense and too short for all the topics worth discussing.
That s all on my side! I really enjoyed this Netfilter workshop round.
Finally, after many interesting debates over two days, the workshop ended. We all agreed on the need for extending
it to 3 days next time, since 2 days feel too intense and too short for all the topics worth discussing.
That s all on my side! I really enjoyed this Netfilter workshop round.
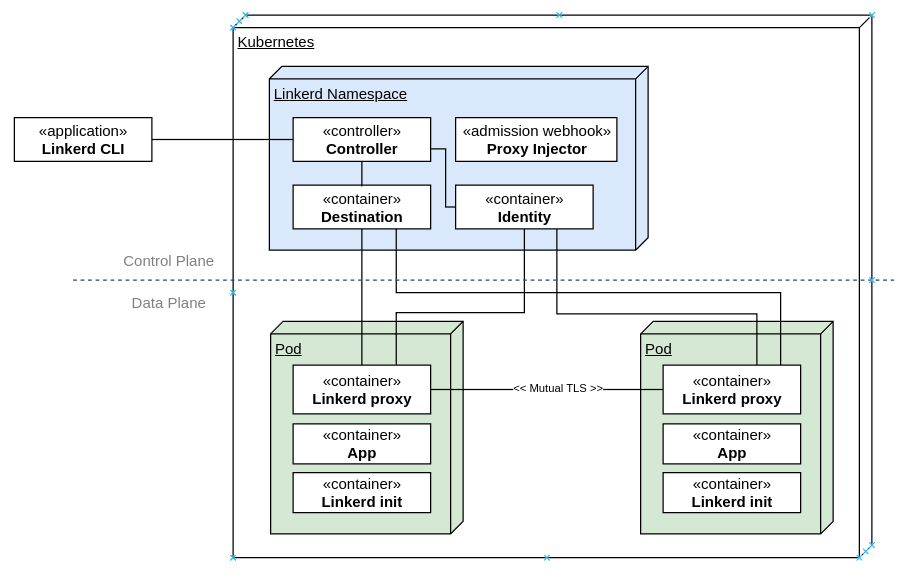
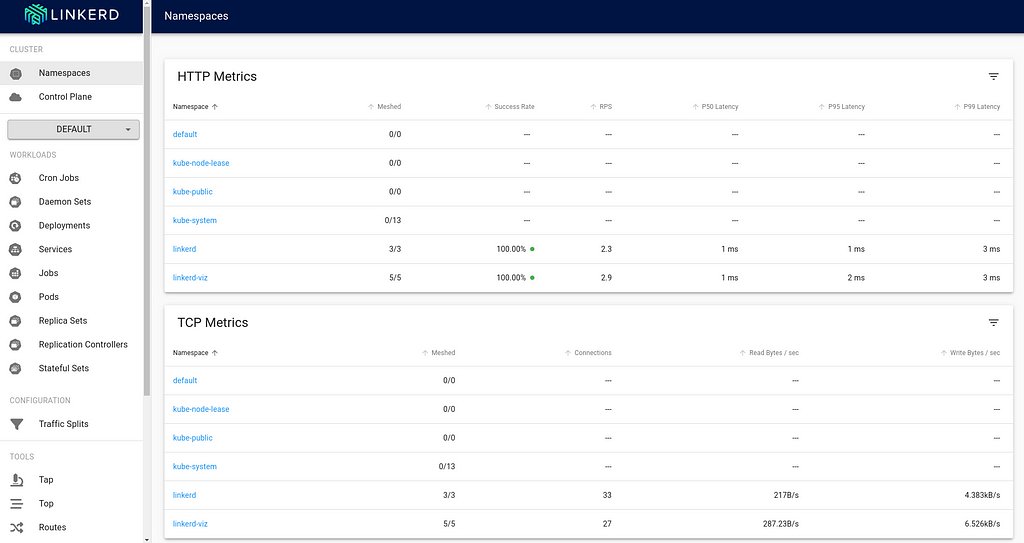
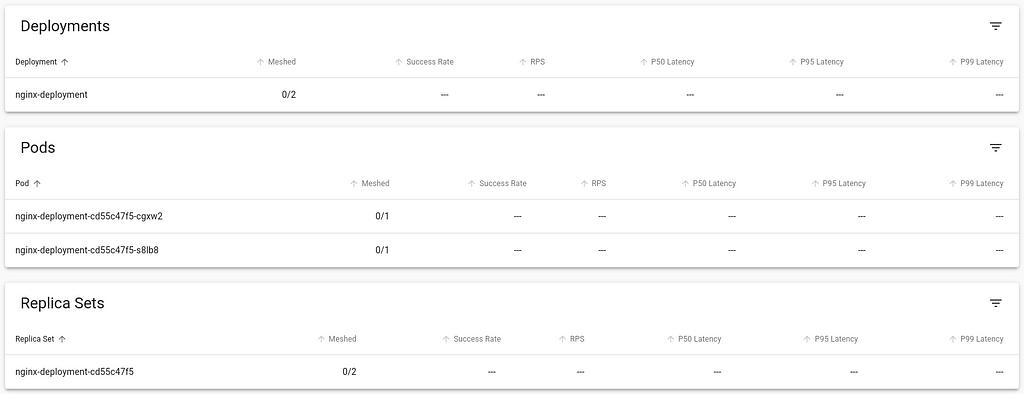
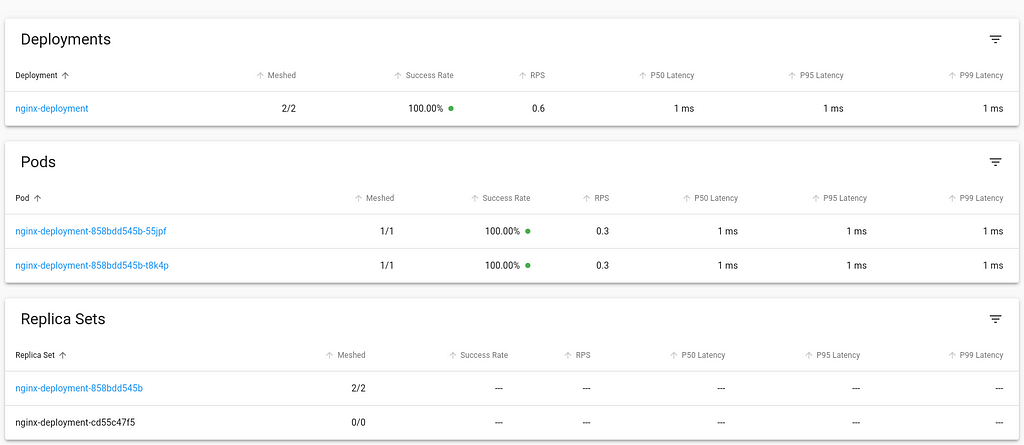
 This post describes how I ve put together a simple static content server for
kubernetes clusters using a Pod with a persistent volume and multiple
containers: an sftp server to manage contents, a web server to publish them
with optional access control and another one to run scripts which need access
to the volume filesystem.
The sftp server runs using
This post describes how I ve put together a simple static content server for
kubernetes clusters using a Pod with a persistent volume and multiple
containers: an sftp server to manage contents, a web server to publish them
with optional access control and another one to run scripts which need access
to the volume filesystem.
The sftp server runs using

{kind=link}
{kind=link}